API
What is the Python SDK API?
The Python SDK is a convenient way to access the Corva Platform API and the Corva Data API.
The Python SDK provides an API object, which wraps the Python requests library and adds automatic authorization, convenient URL usage and reasonable timeouts to API requests. The Python SDK API methods return requests.Response objects.
The Python SDK API can perform the following requests:
- GET
- POST
- PATCH
- PUT
- DELETE
What is the Corva Platform API and Corva Data API?
Corva has two API libraries. The first API library is the Corva Platform API. This API is what Corva is built on. This is what Corva internal developers used to bring data into the Corva apps for the functionality of the Corva Platform.
The second API library is the Corva Data API. This is Corva’s newer API library. This library is what Corva’s SDKs are built on and this API is what is recommended by Corva for Dev Center developers and the majority of API requests made by API users.
The Corva Platform API (https://api.corva.ai/v2/rigs/{id}) is an API that is built on Ruby on Rails framework. The Corva Platform performs requests to both a Corva sequel table and to Corva’s MongoDB datasets.
The Corva Data API (https://data.corva.ai/api/v1/data/{provider}/{dataset}/) is an API that is built on FastAPI framework with similar functionalities and query methods of MongoDB. The Corva Data API only performs requests to Corva’s MongoDB datasets.
When to use the Python SDK API?
The typical use case of when to use the Python SDK API is when you need to query a Corva dataset or your company's dataset in the Dev Center.
- I require to GET historical data from a Corva dataset and/or my company's dataset in the Dev Center
- I require to POST and/or PATCH and/or PUT data in a company dataset in the Dev Center
- I require to DELETE data from a company dataset in the Dev Center
How to use the Python SDK API?
The following examples will demonstrate how to use the Python SDK API.
1. Provide read or write or read and write permissions to the Corva dataset(s)
Permissions can only be provided to MongoDB datasets where there is a {provider} and {dataset}, e.g. /api/v1/data/corva/wits/. Permissions cannot be provided to endpoints e.g. /v2/rigs
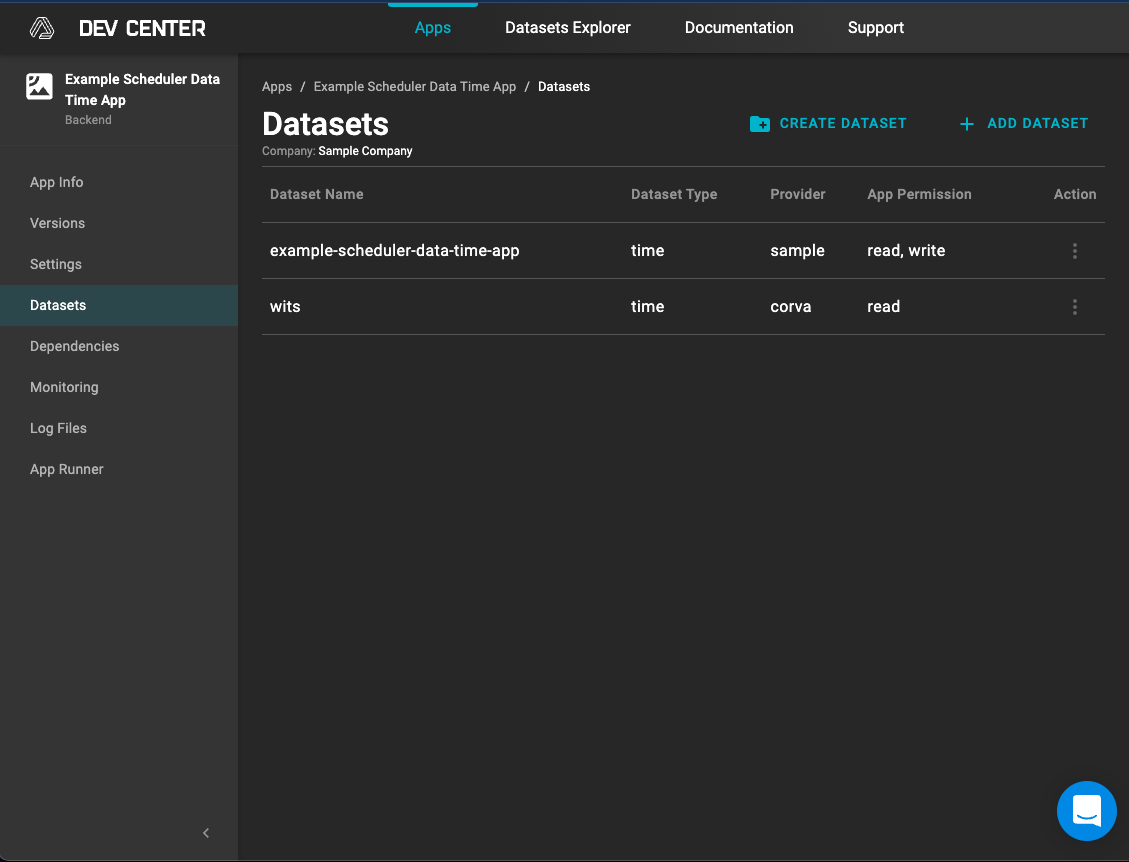 Example of Dataset Permissions in the Dev Center
Example of Dataset Permissions in the Dev Center
"datasets": {
"example.example-scheduler-data-time-app": {
"permissions": [
"read",
"write"
]
},
"corva.wits": {
"permissions": [
"read"
]
}
}
Example of dataset permissions in the manifest.json file
2. How to import the Python SDK API functionality
from corva import Api, Cache, Logger, ScheduledDataTimeEvent, scheduled
Example of importing the Python SDK API functionality into a StreamDataTimeEvent application
3. How to use the Python SDK API GET with the Corva Data API and short URL
If dataset permissions were provided to the app, then the following URL can be used.
# 1. Import required functionality.
from corva import Api, Cache, Logger, ScheduledDataTimeEvent, scheduled
# Importing json to use json.dumps in the query parameters because some of the param values in the query are a dictionary
import json
# 2. - Decorate your function using @scheduled. Use the the existing lambda_handler function or define your own function. It must receive three argumets: event, api and cache. The arguments serve as building blocks for your app.
@scheduled
def lambda_handler(event: ScheduledDataTimeEvent, api: Api, cache: Cache):
# 3. Here is where you can declare your variables from the argument event: ScheduledDataTimeEvent and start using Api, Cache and Logger functionalities.
# The scheduled app can declare the following attributes from the ScheduledDataTimeEvent: company_id: The company identifier; asset_id: The asset identifier; start_time: The start time of interval; end_time: The end time of interval
asset_id = event.asset_id
company_id = event.company_id
start_time = event.start_time
end_time = event.end_time
# 4. Set up the API request parameters
params = {
"query": json.dumps({
"asset_id": asset_id,
"timestamp": {
"$gte": start_time,
"$lte": end_time
}
}),
"limit": 1,
"sort": json.dumps({'timestamp': 1}),
"fields": "data.rop"
}
# 5. Set up the Corva Data API request URL
response = api.get("/api/v1/data/corva/wits/", params=params).json()
# 6. Utilize the Logger functionality.
Logger.debug(f"{response=}")
4. How to use the Python SDK API GET with the Corva Data API and full URL
If dataset permissions were provided to the app, then the following URL can be used.
# 1. Import required functionality.
from corva import Api, Cache, Logger, ScheduledDataTimeEvent, scheduled
# Importing json to use json.dumps in the query parameters because some of the param values in the query are a dictionary
import json
# 2. - Decorate your function using @scheduled. Use the the existing lambda_handler function or define your own function. It must receive three argumets: event, api and cache. The arguments serve as building blocks for your app.
@scheduled
def lambda_handler(event: ScheduledDataTimeEvent, api: Api, cache: Cache):
# 3. Here is where you can declare your variables from the argument event: ScheduledDataTimeEvent and start using Api, Cache and Logger functionalities.
# The scheduled app can declare the following attributes from the ScheduledDataTimeEvent: company_id: The company identifier; asset_id: The asset identifier; start_time: The start time of interval; end_time: The end time of interval
asset_id = event.asset_id
company_id = event.company_id
start_time = event.start_time
end_time = event.end_time
# 4. Set up the API request parameters
params = {
"query": json.dumps({
"asset_id": asset_id,
"timestamp": {
"$gte": start_time,
"$lte": end_time
}
}),
"limit": 1,
"sort": json.dumps({'timestamp': 1}),
"fields": "data.rop"
}
# 5. Set up the Corva Data API request URL
response = api.get("https://data.corva.ai/api/v1/data/corva/wits/", params=params).json()
# 6. Utilize the Logger functionality.
Logger.debug(f"{response=}")
5. How to use the Python SDK API GET with the Corva Platform API and short URL
Permissions cannot be given to Corva Platform API endpoints that do not have a {provider} or {dataset}, e.g. https://api.corva.ai/v2/frac_fleets. To make requests to a Corva Platform API endpoint, the user must provide an API key or a Bearer token in headers.
The example below is using the Secrets feature to securely store an API key.
# 1. Import required functionality. Secrets functionalityy is required for this example
from corva import Api, Cache, Logger, ScheduledDataTimeEvent, scheduled, secrets
# Importing json to use .json() to receive the response in json format
import json
# 2. - Decorate your function using @scheduled. Use the the existing lambda_handler function or define your own function. It must receive three argumets: event, api and cache. The arguments serve as building blocks for your app.
@scheduled
def lambda_handler(event: ScheduledDataTimeEvent, api: Api, cache: Cache):
# 3. Here is where you can declare your variables from the argument event: ScheduledDataTimeEvent and start using Api, Cache and Logger functionalities.
# The scheduled app can declare the following attributes from the ScheduledDataTimeEvent: company_id: The company identifier; asset_id: The asset identifier; start_time: The start time of interval; end_time: The end time of interval
company_id = event.company_id
# 4. Set up headers for authorization and call secrets Key
headers = {
"Authorization": f"{secrets['MY_API_KEY']}"
}
# 5. Set up the API request parameters
params = {
"company": company_id
}
# 6. Set up the Corva Platform API request URL
response = api.get("/v2/rigs", headers=headers, params=params).json()
# 7. Utilize the Logger functionality.
Logger.debug(f"{response=}")
6. How to use the Python SDK API GET with the Corva Platform API and full URL
Permissions cannot be given to Corva Platform API endpoints that do not have a {provider} or {dataset}, e.g. https://api.corva.ai/v2/frac_fleets. To make requests to a Corva Platform API endpoint, the user must provide an API key or a Bearer token in headers.
The example below is using the Secrets feature to securely store an API key.
# 1. Import required functionality. Secrets functionalityy is required for this example
from corva import Api, Cache, Logger, ScheduledDataTimeEvent, scheduled, secrets
# Importing json to use .json() to receive the response in json format
import json
# 2. - Decorate your function using @scheduled. Use the the existing lambda_handler function or define your own function. It must receive three argumets: event, api and cache. The arguments serve as building blocks for your app.
@scheduled
def lambda_handler(event: ScheduledDataTimeEvent, api: Api, cache: Cache):
# 3. Here is where you can declare your variables from the argument event: ScheduledDataTimeEvent and start using Api, Cache and Logger functionalities.
# The scheduled app can declare the following attributes from the ScheduledDataTimeEvent: company_id: The company identifier; asset_id: The asset identifier; start_time: The start time of interval; end_time: The end time of interval
company_id = event.company_id
# 4. Set up headers for authorization and call secrets Key
headers = {
"Authorization": f"{secrets['MY_API_KEY']}"
}
# 5. Set up the API request parameters
params = {
"company": company_id
}
# 6. Set up the Corva Platform API request URL
response = api.get("https://api.corva.ai/v2/rigs", headers=headers, params=params).json()
# 7. Utilize the Logger functionality.
Logger.debug(f"{response=}")
7. How to use the Python SDK API POST with the Corva Data API
If dataset permissions were provided to the app, then the following request can be used. The example below is receiving events from the ScheduledDepthEvent, then making a POST request.
The Corva Python SDK API is built on the Corva Data API and follows the same parameter requirements.
# 1. Import required functionality.
from corva import Api, Cache, Logger, ScheduledDepthEvent, scheduled
# 2. - Decorate your function using @scheduled. Use the the existing lambda_handler function or define your own function. It must receive three argumets: event, api and cache. The arguments serve as building blocks for your app.
@scheduled
def lambda_handler(event: ScheduledDepthEvent, api: Api, cache: Cache):
# 3. Here is where you can declare your variables from the argument event: ScheduledDepthEvent and start using Api, Cache and Logger functionalities.
# The scheduled app can declare the following attributes from the ScheduledDepthEvent: asset_id: The asset identifier; company_id: The company identifier; top_depth: The start depth in ft.; bottom_depth: The end depth in ft.; interval: distance between two schedule triggers; log_identifier: app stream log identifier. Used to scope data by stream. The asset may be connected to multiple depth based logs.
asset_id = event.asset_id
company_id = event.company_id
log_identifier = event.log_identifier
top_depth = event.top_depth
bottom_depth = event.bottom_depth
interval = event.interval
# Utilize the Logger functionality. The default log level is Logger.info. To use a different log level, the log level must be specified in the manifest.json file in the "settings.environment": {"LOG_LEVEL": "DEBUG"}. See the Logger documentation for more information.
Logger.debug(f"{asset_id=} {company_id=} {log_identifier=} {top_depth=} {bottom_depth=} {interval=}")
# 4. This is how to set up a body of a POST request to store the mean dep data and the top_depth and bottom_depth of the interval from the event.
output = {
"asset_id": asset_id,
"company_id": company_id,
"provider": "big-data-energy",
"collection": "example-scheduled-depth-app",
"log_identifier": log_identifier,
"data": {
"interval": interval,
"top_depth": top_depth,
"bottom_depth": bottom_depth
},
"version": 1
}
# Utilize the Logger functionality.
Logger.debug(f"{output=}")
# 5. Post data to a company dataset
# Utilize the API functionality. The data=outputs needs to be an an array because Corva's data is saved as an array of objects. Objects being records. See the API documentation for more information.
api.post("api/v1/data/big-data-energy/example-scheduled-depth-app/", data=[output])
8. How to use the Python SDK API DELETE with the Corva Data API
If dataset permissions were provided to the app, then the following request can be used. The example below is requesting a record from a company dataset, then making a DELETE request of that record.
The Corva Python SDK API is built on the Corva Data API and follows the same URL requirements.
# 1. Import required functionality.
from corva import Api, Logger, TaskEvent, task
# Importing json to use .json() to receive the response in json format
import json
# 2. - Decorate your function using @task. Use the the existing lambda_handler function or define your own function. It must receive two argumets: event and api. The arguments serve as building blocks for your app.
@task
def lambda_handler(event: TaskEvent, api: Api):
# 3. Here is where you can declare your variables from the argument event: TaskEvent and start using Api and Logger functionalities.
# The task app can declare the following attributes from the TaskEvent: company_id: The company identifier; asset_id: The asset identifier.
asset_id = event.asset_id
# 4. Set up the API request parameters
params = {
"query": json.dumps({"asset_id": asset_id}),
"limit": 1,
"sort": json.dumps({"timestamp":-1}),
}
# 5. Set up the Corva Data API GET request URL
response = api.get('/api/v1/data/sample/example-task-app/', params=params).json()
# 6. Utilize the Logger functionality.
Logger.debug(f"{response=}")
# 7. Get the record identifier from the response object
response_id = response[0].get("_id")
# 8. Utilize the Logger functionality.
Logger.debug(f"{response_id=}")
# 9. Set up the Corva Data API DELETE request URL
delete_record = api.delete(f"/api/v1/data/sample/example-task-app/{response_id}/")
# 8. Utilize the Logger functionality.
Logger.debug(f"{delete_record=}")
9. How to use the Python SDK API PUT with the Corva Data API
If dataset permissions were provided to the app, then the following request can be used. The example below is requesting a record from a company dataset, then making a PUT request to replace the requested record.
The Corva Python SDK API is built on the Corva Data API and follows the same URL requirements.
The existing record to be replaced is as follows:
{
"_id":"63bde1fb5a2843b363996575",
"company_id":196,
"asset_id":20173768,
"version":1,
"provider":"sample",
"collection":"example-task-app",
"data":{
"discounted_revenue":1794604,
"discounted_operating_costs":250000,
"drilling_and_completions_costs":1000000,
"npv":544604
},
"timestamp":1673386594
}
The logic to replace the existing record is as follows:
# 1. Import required functionality.
from corva import Api, Logger, TaskEvent, task
# Importing json to use .json() to receive the response in json format
import json
# 2. - Decorate your function using @task. Use the the existing lambda_handler function or define your own function. It must receive two argumets: event and api. The arguments serve as building blocks for your app.
@task
def lambda_handler(event: TaskEvent, api: Api):
# 3. Here is where you can declare your variables from the argument event: TaskEvent and start using Api and Logger functionalities.
# The task app can declare the following attributes from the TaskEvent: company_id: The company identifier; asset_id: The asset identifier.
asset_id = event.asset_id
company_id = event.company_id
# 4. Set up the API request parameters
params = {
"query": json.dumps({"asset_id": asset_id}),
"limit": 1,
"sort": json.dumps({"timestamp":-1}),
}
# 5. Set up the Corva Data API GET request URL
response = api.get('/api/v1/data/sample/example-task-app/', params=params).json()
# 6. Utilize the Logger functionality.
Logger.debug(f"{response=}")
# 7. Get the record identifier from the response object
response_id = response[0].get("_id")
# 8. Utilize the Logger functionality.
Logger.debug(f"{response_id=}")
# 9. Set up body of new record
output = {
"_id": response_id,
"asset_id": asset_id,
"company_id": company_id,
"provider": "sample",
"collection": "example-task-app",
"data": {
"discounted_revenue": 1310539,
"discounted_operating_costs": 166667,
"drilling_and_completions_costs": 1000000,
"npv": 143872
},
"version": 1,
"timestamp": timestamp
}
# Utilize the Logger functionality.
Logger.debug({f"{output=}"})
# 10. Set up the Corva Data API PUT request URL.
# The data=outputs needs to be an an object and not an array.
# Unlike the api.post() method where the data=outputs needs to be an array because Corva's data is saved as an array of objects, the api.put() method is replacing a single object.
put_record = api.put(f"/api/v1/data/sample/example-task-app/{response_id}/", data=output)
# 11. Utilize the Logger functionality.
Logger.debug(f"{put_record=}")
10. How to use the Python SDK API PATCH with the Corva Data API
If dataset permissions were provided to the app, then the following request can be used. The example below is requesting a record from a company dataset, then making a PATCH request to update the requested record.
The Corva Python SDK API is built on the Corva Data API and follows the same URL requirements.
The existing record to be updated is as follows:
{
"_id":"63bde1fb5a2843b363996575",
"company_id":196,
"asset_id":20173768,
"version":1,
"provider":"sample",
"collection":"example-task-app",
"data":{
"discounted_revenue":1310539,
"discounted_operating_costs":166667,
"drilling_and_completions_costs":1000000,
"npv":143872
},
"timestamp":1673386752,
"app_key":"sample.example_task_app"
}
The logic to update the existing record is as follows:
# 1. Import required functionality.
from corva import Api, Logger, TaskEvent, task
# Importing json to use .json() to receive the response in json format
import json
# 2. - Decorate your function using @task. Use the the existing lambda_handler function or define your own function. It must receive two argumets: event and api. The arguments serve as building blocks for your app.
@task
def lambda_handler(event: TaskEvent, api: Api):
# 3. Here is where you can declare your variables from the argument event: TaskEvent and start using Api and Logger functionalities.
# The task app can declare the following attributes from the TaskEvent: company_id: The company identifier; asset_id: The asset identifier.
asset_id = event.asset_id
company_id = event.company_id
# 4. Set up the API request parameters
params = {
"query": json.dumps({"asset_id": asset_id}),
"limit": 1,
"sort": json.dumps({"timestamp":-1}),
}
# 5. Set up the Corva Data API GET request URL
response = api.get('/api/v1/data/sample/example-task-app/', params=params).json()
# 6. Utilize the Logger functionality.
Logger.debug(f"{response=}")
# 7. Get the record identifier from the response object
response_id = response[0].get("_id")
# 8. Utilize the Logger functionality.
Logger.debug(f"{response_id=}")
# 9. Set up body of new record
output = {
"company_id": company_id,
"version":1,
"data":{
"discounted_revenue":2673693,
"discounted_operating_costs":500000,
"drilling_and_completions_costs":1000000,
"npv":1173693
}
}
# Utilize the Logger functionality.
Logger.debug({f"{output=}"})
# 10. Set up the Corva Data API PATCH request URL.
# The data=outputs needs to be an an object and not an array.
# Unlike the api.post() method where the data=outputs needs to be an array because Corva's data is saved as an array of objects, the api.patch() method is updating a single object.
patch_record = api.patch(f"/api/v1/data/sample/example-task-app/{response_id}/", data=output)
# 11. Utilize the Logger functionality.
Logger.debug(f"{patch_record=}")
11. How to use the Python SDK API custom Headers
The example below show how to use headers with the Secretes feature when making a GET request.
# 1. Import required functionality. Secrets functionalityy is required for this example
from corva import Api, Cache, Logger, StreamTimeEvent, stream, secrets
# Importing json to use .json() to receive the response in json format
import json
# 2. - Decorate your function using @stream. Use the the existing lambda_handler function or define your own function. It must receive three argumets: event, api and cache. The arguments serve as building blocks for your app.
@stream
def lambda_handler(event: StreamTimeEvent, api: Api, cache: Cache):
# 3. Here is where you can declare your variables from the argument event: StreamTimeEvent and start using Api, Cache and Logger functionalities. You can obtain key values directly from metadata in the stream app event without making any additional API requests.
# You have access to asset_id, company_id, and real-time data records from event.
company_id = event.company_id
# 4. Set up headers for authorization and call secrets Key
headers = {
"Authorization": f"{secrets['MY_API_KEY']}"
}
# 5. Set up the API request parameters
params = {
"company": company_id
}
# 6. Set up the Corva Platform API request URL
response = api.get("https://api.corva.ai/v2/pads", headers=headers, params=params).json()
12. How to use the Python SDK API custom Timeout
The example below show how to use timeout making a GET request.
The max timeout for an API request is 30 seconds.
# 1. Import required functionality. Secrets functionalityy is required for this example
from corva import Api, Cache, Logger, StreamTimeEvent, stream, secrets
# Importing json to use .json() to receive the response in json format
import json
# 2. - Decorate your function using @stream. Use the the existing lambda_handler function or define your own function. It must receive three argumets: event, api and cache. The arguments serve as building blocks for your app.
@stream
def lambda_handler(event: StreamTimeEvent, api: Api, cache: Cache):
# 3. Here is where you can declare your variables from the argument event: StreamTimeEvent and start using Api, Cache and Logger functionalities. You can obtain key values directly from metadata in the stream app event without making any additional API requests.
# You have access to asset_id, company_id, and real-time data records from event.
company_id = event.company_id
# 4. Set up headers for authorization and call secrets Key
headers = {
"Authorization": f"{secrets['MY_API_KEY']}"
}
# 5. Set up the API request parameters
params = {
"company": company_id
}
# 6. Set up the Corva Platform API request URL
response = api.get("https://api.corva.ai/v2/frac_fleets", headers=headers, params=params,timeout=30).json()
13. How to use the Python SDK API Convenience Method
Api provides a convenience method for frequently used endpoints. The Convenience method can only be used with the Corva Data API.
The following example shows how to use the Convenience Method.
# 1. Import required functionality.
from corva import Api, Cache, Logger, ScheduledDepthEvent, scheduled
# 2. - Decorate your function using @scheduled. Use the the existing lambda_handler function or define your own function. It must receive three argumets: event, api and cache. The arguments serve as building blocks for your app.
@scheduled
def lambda_handler(event: ScheduledDepthEvent, api: Api, cache: Cache):
# 3. Here is where you can declare your variables from the argument event: ScheduledDepthEvent and start using Api, Cache and Logger functionalities.
# The scheduled app can declare the following attributes from the ScheduledDepthEvent: asset_id: The asset identifier; company_id: The company identifier; top_depth: The start depth in ft.; bottom_depth: The end depth in ft.; interval: distance between two schedule triggers; log_identifier: app stream log identifier. Used to scope data by stream. The asset may be connected to multiple depth based logs.
asset_id = event.asset_id
company_id = event.company_id
log_identifier = event.log_identifier
top_depth = event.top_depth
bottom_depth = event.bottom_depth
interval = event.interval
# 4. Utilize the attributes from the ScheduledDepthEvent to make an API request to corva#drilling.wits.depth or any desired depth type dataset using the following Corva Python SDK API formatting.
records = api.get_dataset(
provider="corva",
dataset= "drilling.wits.depth",
query={
'asset_id': asset_id,
'log_identifier': log_identifier,
'measured_depth': {
'$gte': top_depth,
'$lte': bottom_depth,
},
},
sort={'measured_depth': 1},
limit=500,
fields="data.rop"
)